今天介紹讀取netCDF(network Common Data Form),主要介紹可點這。
那netCDF有很多版,現行主要用的有netCDF3或netCDF4,而netCDF4是在hdf5基礎上建立的。所以代入前面幾天說的函式庫概念,netcdf的函式庫在編譯時,是可以連結hdf5的函式庫,這樣編譯完成的netcdf就可以讀取netcdf4及hdf5的資料格式。來去conda網頁看一下,截圖如下,可以看到欲使用編譯好的netcdf4套件是有連結hdf5的函式庫。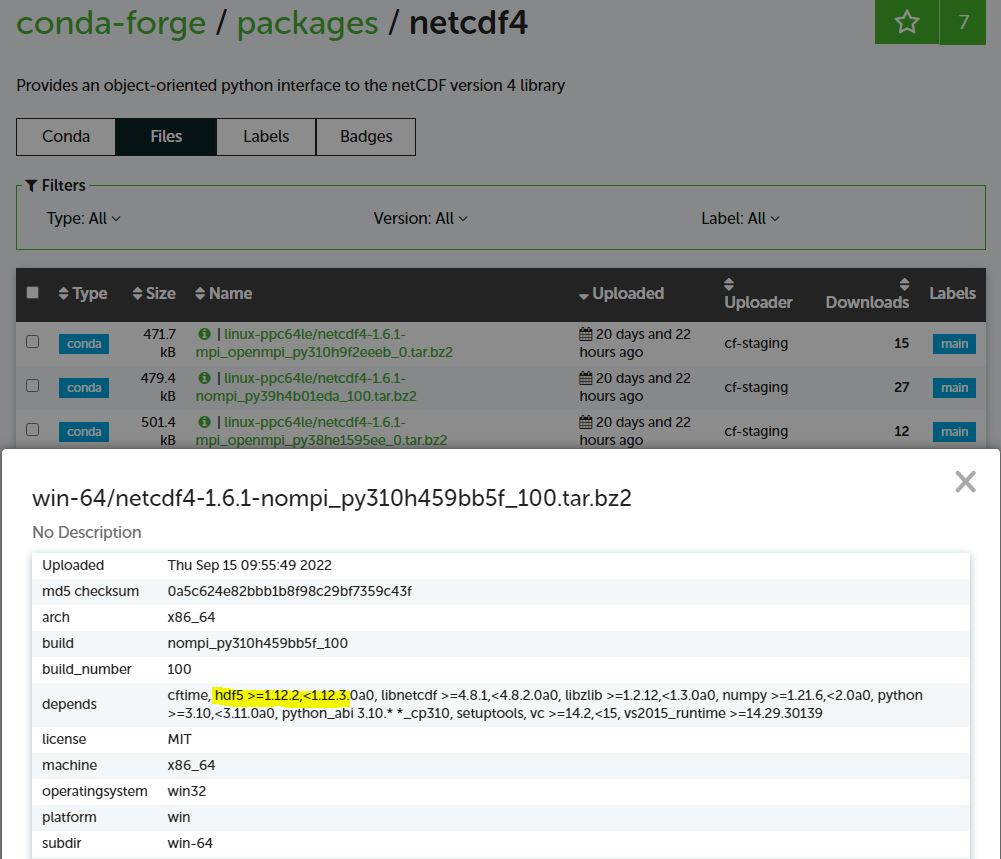
先安裝套件
conda install -c conda-forge netcdf4
或
pip3 install netcdf4
另外還有其他的套件也可以解netcdf4檔案,譬如xarray, gdal(沒錯,又再次出現)等
由於我手邊沒有數值模式直接輸出的netcdf檔案,就改用opendata提供的grib2轉成netcdf3及netcdf4的格式。
為什麼要轉成netcdf3及netcdf4呢?我只是要顯示壓縮效率。如下圖,.nc結尾的檔案為netcdf3格式,.nc4結尾的為netcdf4格式,有沒有發現netcdf4格式的檔案比較小呢?所以,真的不要再用netcdf3了。
現在來讀取資料
import netCDF4 as nc4
nc4 = nc4.Dataset("day22/M-A0064-21091006-048.nc4")
print(nc4.variables.keys())
'''
上面會得到-
dict_keys(['y', 'x', 'latitude', 'longitude', 'time', 'HGT_100mb', 'TMP_100mb', 'UGRD_100mb', 'VGRD_100mb', 'DZDT_100mb', 'RH_100mb', 'HGT_150mb', 'TMP_150mb', 'UGRD_150mb', 'VGRD_150mb', 'DZDT_150mb', 'RH_150mb', 'HGT_200mb', 'TMP_200mb', 'UGRD_200mb', 'VGRD_200mb', 'DZDT_200mb', 'RH_200mb', 'HGT_250mb', 'TMP_250mb', 'UGRD_250mb', 'VGRD_250mb', 'DZDT_250mb', 'RH_250mb', 'HGT_300mb', 'TMP_300mb', 'UGRD_300mb', 'VGRD_300mb', 'DZDT_300mb', 'RH_300mb', 'HGT_400mb', 'TMP_400mb', 'UGRD_400mb', 'VGRD_400mb', 'DZDT_400mb', 'RH_400mb', 'HGT_500mb', 'TMP_500mb', 'UGRD_500mb', 'VGRD_500mb', 'DZDT_500mb', 'RH_500mb', 'HGT_700mb', 'TMP_700mb', 'UGRD_700mb', 'VGRD_700mb', 'DZDT_700mb', 'RH_700mb', 'HGT_850mb', 'TMP_850mb', 'UGRD_850mb', 'VGRD_850mb', 'DZDT_850mb', 'RH_850mb', 'HGT_925mb', 'TMP_925mb', 'UGRD_925mb', 'VGRD_925mb', 'DZDT_925mb', 'RH_925mb', 'PRES_surface', 'APCP_surface', 'TMP_2maboveground', 'DPT_2maboveground', 'SPFH_2maboveground', 'RH_2maboveground', 'UGRD_10maboveground', 'VGRD_10maboveground', 'HGT_1000mb', 'TMP_1000mb', 'UGRD_1000mb', 'VGRD_1000mb', 'DZDT_1000mb', 'RH_1000mb', 'TMP_surface', 'NSWRS_surface', 'PRMSL_meansealevel', 'SKINT_surface'])
'''
上述字典內的key值,代表的是這一份netcdf檔案中有的變數。要選取的話,直接用字典的方式選取即可。
print(nc4["latitude"])
'''
會得到
<class 'netCDF4._netCDF4.Variable'>
float64 latitude(y, x)
units: degrees_north
long_name: latitude
unlimited dimensions:
current shape = (673, 1158)
filling on, default _FillValue of 9.969209968386869e+36 used
'''
上述以取緯度為例,會發現這是一些描述檔案,譬如緯度的維度大小為673乘以1158,如果要取值的話,直接使用[:]即可。
lat = nc4["latitude"][:] #這樣就取到緯度的值
#那如果是三維的變數值,方式如下
u10 = nc4["UGRD_10maboveground"][0] #u10的維度為3維(1,673,1158)
像這樣的數值模式資料,取出來的變數資料通常是以numpy mask array為主,所以有的時候記得要熟悉numpy mask的方法才能夠妥善處理,不然也是只取data的部分(把mask部分丟掉,或改成np.nan,因為通常mask起來的地方都是無效值)。
今天差不多說到這,明天就來視覺化吧

